SLM Profile RAG Chatbot
Profile-aware RAG chatbot that prioritizes a main document, retrieves vectorized resume/profile data, and serves responses locally via Ollama + Streamlit.
Overview
Overview
A Python-native RAG chatbot for professional profiles. It ingests resumes, project writeups, and portfolio docs, embeds them into ChromaDB, and serves grounded answers locally through Ollama with a Streamlit UI so recruiters can “interview” your work—not just skim a PDF.
Motivation
Job interviews can feel like a performance tax, especially for introverts who know the work but stumble under pressure. I built this in a weekend so quieter developers can let their work speak for itself. The stack is transparent and configurable: fork it, drop in your docs, tune YAML, and deploy a shareable chatbot (HF Spaces or local).
Tech Stack & Architecture
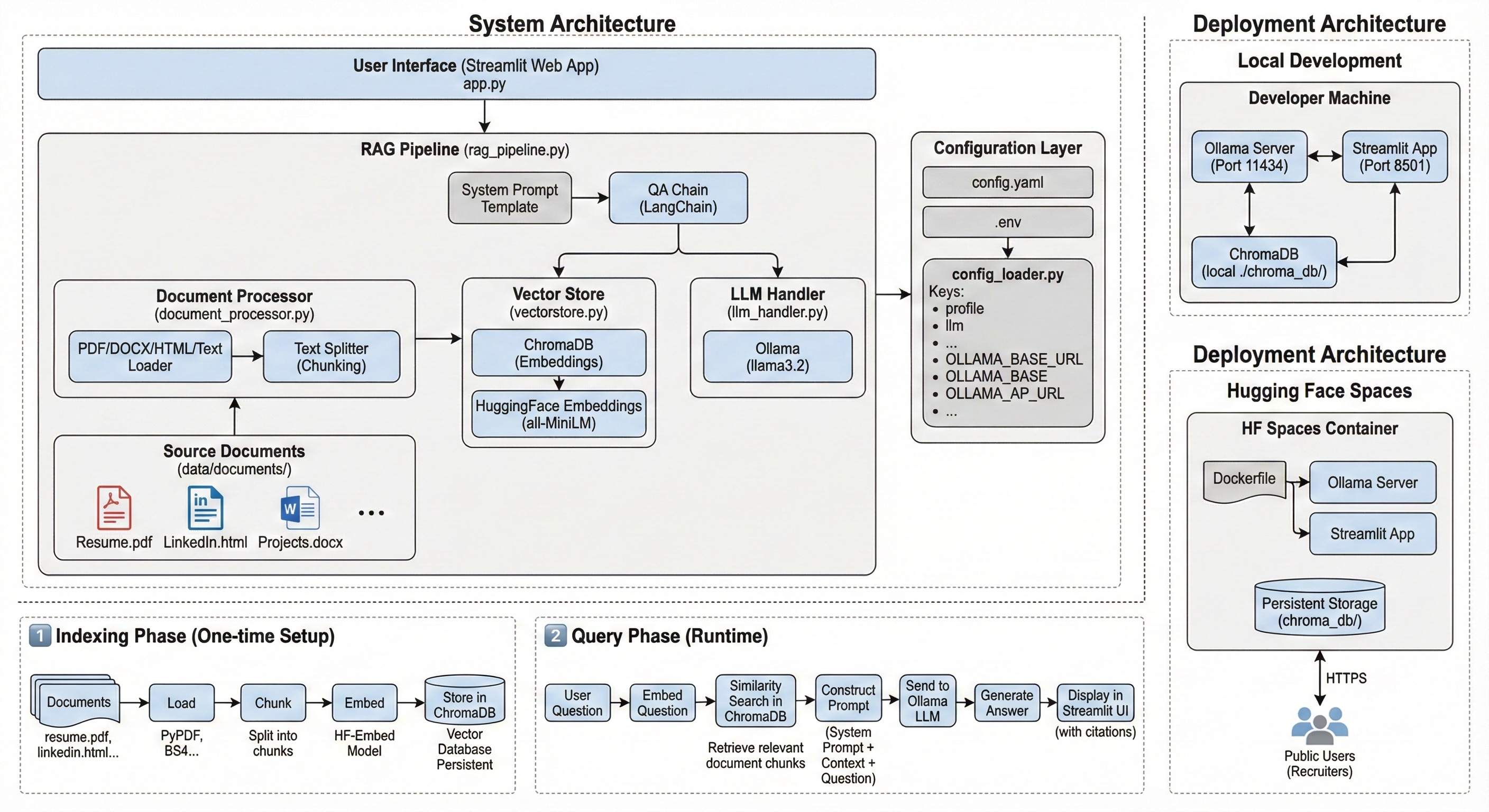
Architecture overview of the SLM Profile RAG stack
- UI: Streamlit chatbot, shareable link for recruiters/hiring managers.
- RAG Pipeline (LangChain): RetrievalQA chain stitching prompt, retriever, and LLM.
- Vector Store: ChromaDB (persistent) + all-MiniLM embeddings; similarity/MMR search.
- LLM Serving: Ollama with small, fast models (llama3.2:3b recommended; phi3:mini, gemma2:2b; llama3.1:8b with GPU).
- Config-First: YAML persona/model/chunking;
.envoverrides for URLs/paths; no hard-coding. - Packaging: UV + Hatchling + Versioningit; Ruff for lint/format; Docker image for HF Spaces.
- Document Processing: PDF/DOCX/HTML/MD/TXT loaders with configurable chunk size/overlap; optional prioritized main document for guaranteed context.
- Response Polishing: Optional enhancer for concise, recruiter-friendly tone with citations.
Workflow
- Indexing:
python -m src.build_vectorstoreto load, chunk, embed, and persist documents in ChromaDB. - Query: Embed question, retrieve top-k chunks, compose prompt, and answer via Ollama with citations in Streamlit.
- Config Tweaks: Swap models, adjust chunking, or change persona via
config.yamland.env.
Deployment and Packaging
- Local: Streamlit + Ollama + local ChromaDB.
- Hugging Face Spaces: Docker-based Space installs Ollama, pulls model, restores persistent
chroma_db, and serves the app over HTTPS. - Build System: UV + Hatchling with Versioningit for git-tag-based versions; Ruff for lint/format.
- Config:
.envoverridesconfig.yaml(model, chunking, paths).
Why It Matters
- Lets your work speak when interviews get noisy—grounded answers from your own corpus.
- Privacy-first: runs locally by default; no external API calls required.
- Portable and shareable: one-click HF Space or run on a laptop with small models.
- Transparent and teachable: clean Python stack to learn RAG end-to-end.
Example UI
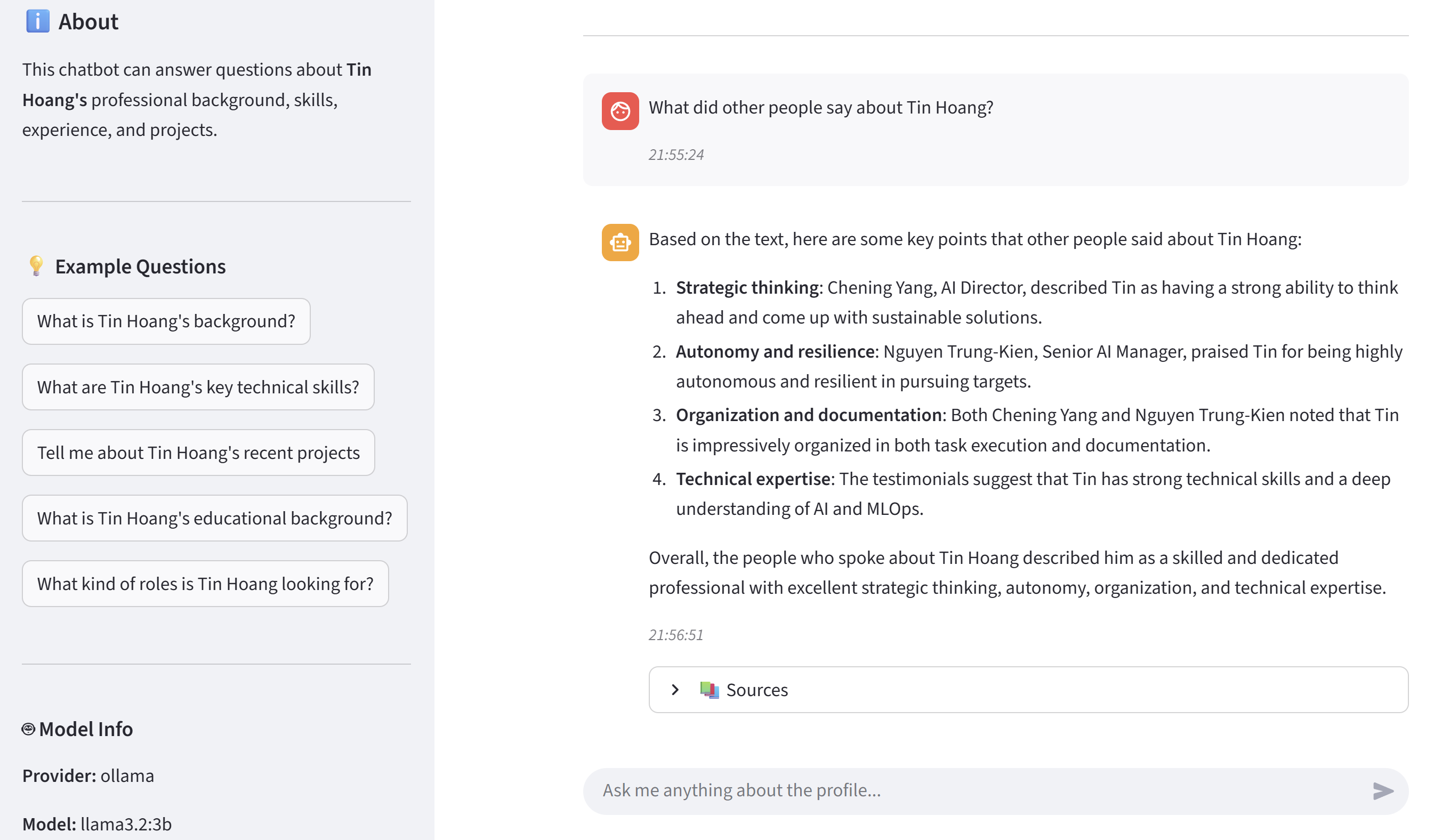
Streamlit chatbot interface showing the profile-aware assistant
Key Achievements
- Built a priority main-document pipeline with auto-format detection, token-aware trimming, and hash-based caching so critical profile info always stays in context.
- Delivered semantic retrieval over resume/profile corpora using ChromaDB + all-MiniLM embeddings with similarity/MMR search and 10k-token context budgeting.
- Packaged for Hugging Face Spaces with Ollama-served small models (llama3.2:3b, phi3:mini, gemma2:2b) and persistent vector storage for reproducible answers.
Technologies Used
Skills Applied
Project Details
Role
Builder
Team Size
Individual
Duration
a weekend project on Nov 2025
Want to know more about this project?
Ask my AI