LODENet: Offline Handwritten Chinese and Japanese Text Recognition
Novel OCR model for handwritten Chinese and Japanese text line recognition achieving SOTA accuracy, published in ICPR 2020.
Overview
Led the development of LODENet, a holistic approach to offline handwritten Chinese and Japanese text line recognition. Proposed a novel encoding method (LODEC) that efficiently performs 1-to-1 mapping for all Chinese and Japanese characters with strong semantic awareness. LODEC enables encoding over 21,000 characters using only 520 fundamental elements—a breakthrough in handling the massive character vocabulary of logographic scripts.
The Challenge
Handwritten Chinese and Japanese text recognition faces unique challenges:
- Massive Character Vocabulary: The Kangxi dictionary has over 47,000 Kanji characters; common usage requires 21,000+ characters
- Complex Character Structures: Characters consist of unique sets of radicals and basic components with distinctive semantic meanings
- High Visual Similarity: Many characters differ by subtle stroke variations
- Diverse Handwriting Styles: Erased texts, connected characters, and personal style variations
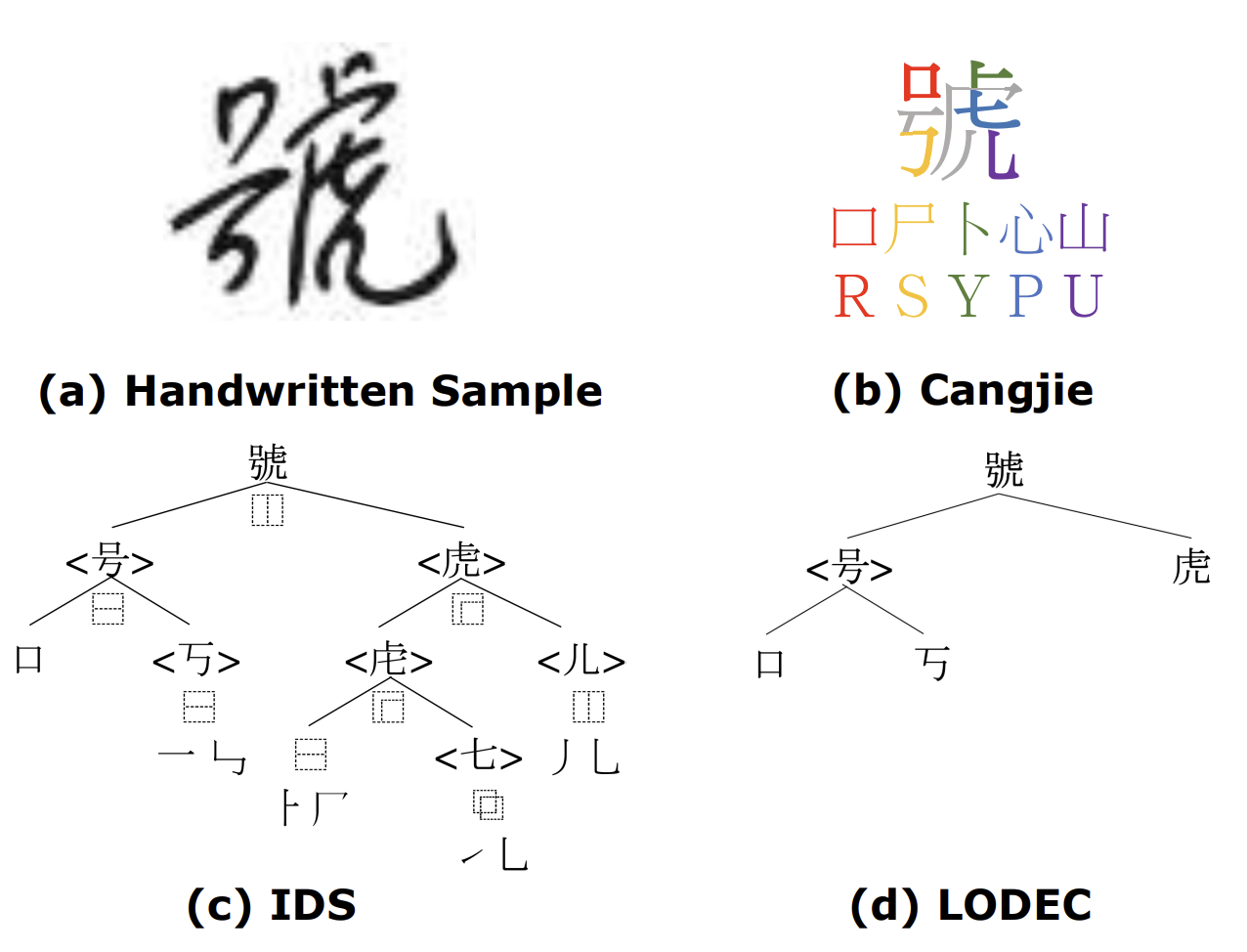
Existing encoding solutions like Cangjie and Ideographic Description Sequences (IDS) have critical limitations—they are not bijective (1-to-1 mappings), creating ambiguous transcriptions that confuse deep learning models.
LODEC: Our Novel Encoding
LOgographic DEComposition encoding (LODEC) is a bijective encoding method designed specifically for deep learning applications.
Key Properties
- Compact Representation: 520 selective radicals encode 21,448 Kanji Unicode characters
- Bijective Mapping: Guarantees unique 1-to-1 encoding for every character
- Semantic Awareness: Characters sharing radicals have similar encodings
- Optimized for DL: Shorter encoding lengths than IDS with comparable expressiveness
Comparison with Existing Methods
| Method | No. of Codes | Bijective | Encoding Length |
|---|---|---|---|
| One-hot | 21,448 | Yes | 21,448 ± 0 |
| Cangjie | 26 | No | 109 ± 19 |
| IDS | 387 | No | 3,618 ± 1,722 |
| LODEC (Ours) | 520 | Yes | 1,856 ± 691 |
Japanese Kana Support
Japanese Kana characters are decomposed into unique tuples of voiced consonants and pronunciation changes. For example, ボ is encoded as a combination of ホ and the dakuten ゛.
LODENet Architecture
The LODENet model introduces a novel Conversion Network (CN) that learns to transcribe from radical-based features to character outputs.
Visual Feature Extractor
- Input: 1-channel grayscale image (height 64px, flexible width)
- CNN Backbone: Customized VGG-style network with 4 max-pooling layers
- Sequential Modeling: Bidirectional GRU (BGRU) with 512 hidden units for radical prediction
Conversion Network (CN)
The novel CN converts radical logits to character logits using:
- Inception-style Convolutions: 4 parallel 1D convolutions with kernel sizes 1×1, 1×3, 1×5, and 1×7
- 1×1 kernels: For non-decomposable characters
- Larger kernels: For groups of radicals forming composable characters
- Sequential GRU: Captures relationships between radicals for character prediction
Dual CTC Loss Training
An end-to-end training scheme using weighted dual CTC losses:
- CTC_logo: Character-level loss using ground truth sequences
- CTC_radi: Radical-level loss using LODEC decomposed sequences
Results
SCUT-EPT Dataset (Chinese)
| Model | AR (%) | CR (%) |
|---|---|---|
| CNN + LSTM + CTC | 75.97 | 80.26 |
| CMAM | 74.45 | 82.14 |
| LODENet (Ours) | 76.61 | 82.91 |
| LODENet + Synthetic Data | 77.36 | 84.64 |
Private Japanese Dataset (CER)
| Model | Validation CER | Test CER |
|---|---|---|
| CMAM | 17.55 | 12.99 |
| LODENet (Ours) | 11.70 | 5.47 |
LODENet achieved 58% relative error reduction on the Japanese test set compared to CMAM baseline.
Key Findings from Ablation Studies
- LODEC + LODENet significantly outperformed Cangjie and IDS combinations (p < 1e-7)
- Synthesized training data improved accuracy by 5%+ on CASIA without domain knowledge
- The Conversion Network is essential—removing it causes significant performance drops
Impact
- Publication: ICPR 2020 (25th International Conference on Pattern Recognition)
- Patent: Filed at Japan Patent Office (JP-2022160140-A)
- Production Use: Deployed in 20+ B2B client projects across document digitization
- Recognition: Multiple "project hero" awards at Cinnamon AI
- Research Team: Collaboration between Cinnamon AI Labs and University of Oulu
Key Achievements
- Achieved SOTA accuracy on SCUT-EPT and Japanese datasets
- Published paper in ICPR 2020
- Filed patent at Japan Patent Office (2021)
- Model used in over 20 client projects
Technologies Used
Skills Applied
Project Details
Role
AI Researcher (Model Author)
Team Size
5
Duration
Oct 2018 - Sep 2019
Links
Want to know more about this project?
Ask my AI